深度学习中标签思维的局限
在生活中,聪明的人常常告诫我们,不要给事物轻易下定义,不要轻易给他人打上标签,因为“标签”的一种贬义替代词汇是“偏见”。然而目前的机器学习正利用人类的标签思维进行学习,所以机器学习到头来,学习到的都是我们的偏见吗?
端到端是标签思维的一种表现
我们首先来谈论一下端到端的学习。什么是端到端学习?简单来讲就是,机器学习一个从特定输入到特定输出的过程。端到端的学习应该在深度学习产生后进入了巅峰状态。对物体特征的提取技术由手工设计,如(HOG、Har、SIFT、LBP等),被自动提取技术(CNN)所替代了,少了人工的介入,那么端到端就能够轻易实现了。但实际上,端到端是一种局限的智能,为什么说它是局限的?一方面,它导致了模型的黑箱化,不可解释性,即我们不能认知中间特征数据所表示的内涵,另外,一个样本的信息量是巨大的,若是从不同的角度去解读,提取它的内涵就会得到不同的“标签”,甚至可以提取出内涵对立的标签(比如,如果我们特意地让机器去区分人类和动物的差异,机器就不能学习到,人类本身就是动物,这一基本事实),然而机器将大量相似的图像进行归纳学习为一个单独的标签,那么模型学到的是一种呆板的、偏见的抽象,这绝对不是真正的智能,就像Judeal Pearl说的如今的机器学习就是曲线拟合而已。
标签思维导致对抗样本的产生
近来的研究表明 DNN 容易受到对抗样本(adversarial example)的影响:在输入中加入精心设计的对抗扰动(adversarial perturbation)可以误导目标 DNN,使其在运行中给该输入加标签时出错。
一个常见的对抗攻击来自于2014年Goodfellow提出的Fast Gradient Sign Method(FGSM),它通过在梯度方向上进行添加增量来诱导网络对生成的图片X’进行误分类 \[ x^{,}=x+\varepsilon sign(\bigtriangledown _{x} J(\theta ,x,y)) \]
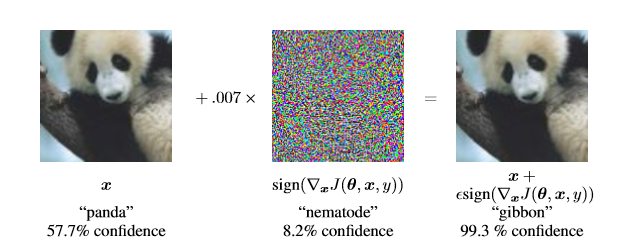
在图片样本加上精心设计的噪声干扰后,机器会以99.3%的置信度认为图片中动物是长臂猿,而不是熊猫!
当在实际世界中应用 DNN 时,这样的对抗样本就会带来安全问题。比如,加上了对抗扰动的输入可以误导自动驾驶汽车的感知系统,使其在分类道路标志时出错,从而可能造成灾难性的后果。

谷歌团队的这篇论文Adversarial Spheres,从流形的角度探讨了对抗样本的产生
对抗样本的破坏能力之所以强大,是因为DNN就没有根本理解图像的内涵,它把标签实际当成了图像中一种可以进行量化的真实属性值,学到的是这个“属性”和其他层次属性(如颜色,纹理,布局,边缘等)的映射关系,这种手工标签和智能所理解的“标签”是有本质的区别的。
手工设计的标签:表示通过设定阈值得到的属性概念的对立程度。比如即图像中一只狗,这种手工标签表示的是“是狗”和“不是狗”这两种概念的对立程度
人类智能的“标签”:表示和很多低层信息,中层概念紧密相连,甚至同时存在的一种整体概念连接关系,而不是单纯的表示概率的标量。我们提到标签“狗”时,这个“狗”绝不是单个标量,而是和动物、摇尾巴、宠物、躯干、四肢、舌头、毛发等并行存在的概念。
对于同一种“标签”来说,它的图像差异可能非常大,甚至出现对立,如果你用深度学习去学习像素到标签的映射是非常困难,难以收敛的,或者容易过拟合,所以一些被认为是正常的标签,模型并不认识。
还有,幽默理论认为:人之所以会笑,是因为突然觉察到概念和实物之间关系的不协调,笑就是对这种不协调之间的反映,所以事物的概念并不是一种固化的东西。
对抗样本与“标签”空间
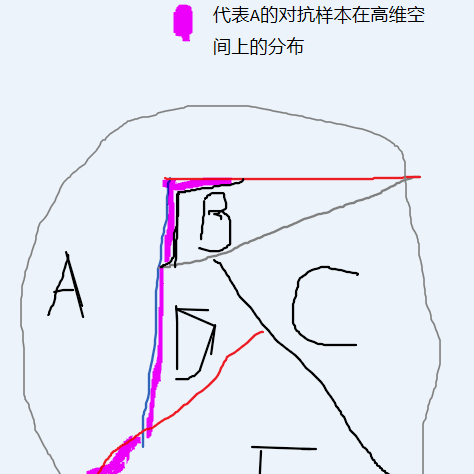
对抗样本的产生函数:就是利用了标签思维的局限性,利用这一弱点,设计出标签为 A,但是与B(C,D……)类的像素度量距离更近的样本(即,肉眼观察更接近B,C,D,或者指定如C)。
一般的神经网络其实也是在高维数据空间,寻找多个分界面,作为类与类的区别
无论模型训练出何种程度,一定可以在高维空间的分界面处寻找到A的对抗样本,数据维度越高,对抗样本在展开维空间上越相似于A,但实际却属于B,所以增加模型参数,有利于寻找对抗样本
标签思维,就是在扭曲、折叠客观实在的空间中,寻找一个高维流形球,球内球外,作为一个“标签”的判断依据,所以你在图像上,描一个轻微的线,只要你能将被加了一条线的图像样本在扭曲空间中实现一次在分界流形球面的“超球面穿越”,那么这个加工后的图片就能成为对抗样本。所以对抗样本的存在与标签思维训练是一个硬币的正反面,是共同存在的,当下所有用标签训练出来的深度学习模型,无论它声称的鲁棒性有多好,在理论上都是存在一些对抗样本能够完全地混淆模型的预测,如Adversarial Spheres中所述。
从标签到实体,概念如何表征?
智能需要多种定义,一种泛化的概念,打破局限的标签思维。标签应该从概念实体中产生,角度不同,标签不同 Hinton2017年提出的capsules,最后一层用活动向量来表示实体,实际上就是从标签思维到概念实体思维的一种突破。另外,深度学习去自主学习低层特征,而不是人工设计特征,这一点是可取的,但是对特征的利用环节,应当引入更多可以设计的接口。这是因为我们人脑的处理信息过程中,从底层的像素信息不是直接映射到概念,中间存在很多层次化的结构,在DNN中是一种粗暴的学习,所以对抗样本才会抓住这一漏洞。而加入一些可介入的中层概念接口,就会提升网络的鲁棒性。
单一标签描述图片是否可靠?
我们先看下列6幅图片,从一般的标签思维出发,其中有4张可以被认为是狗,另外2张被认为是海狮,但是其中几张并不是纯粹的动物照片,而是加入了人为的干扰因素,比如狗穿上了人的服装或者场景的差异。





以上的所有图片,如果按照 标签思维 来分类的话,那么一共有两类:狗和海狮,这两类是如何产生的呢?
首先,我们最关注的是图像的主题信息,也就是包含信息最多的部分,一般占据了图像大部分面积,然后我们发现主题信息都是动物,那么动物的种类就完全作为了我们给图像标签的依据(这是机器学习不到的依据)
然后根据我们的经验,我们通过,耳朵,四肢,毛发长度,脸部五官的分布来区分两个种类。但是其中两幅图有干扰信息,比如人的衣服,帽子,眼镜,这样的干扰对小样本学习来说是致命的,机器很难去忽略此类明显信息而只关注主体,它们让类内差异变得巨大,而第一幅狗的图和两张海狮图,主体信息很明确,基本没有什么干扰,而让机器直接去关注主体的特征之间的差异,甚至可能将其归为一类物体。只有在样本足够足够大时,机器才能学会忽略次要信息,来关注主题信息,这也就是为什么目前的机器学习是需要大数据作支撑的,而非人类的小样本学习。 > 它们都属于动物的这一基本事实,却完全不能用深度网络所学习到的标签表示,也就是说,深度学习训练用到的标签思维,完全是,先利用人类认识事物的基本属性的先验后,再利用图像像素层面寻找数据集中数据分布的差异,然后用几个标量值来表示这种差异的程度,
这也就是我们 标签思维 去训练物体的固有缺陷,总结一下人类所谓的“标签思维”:
人类的标签思维,是忽略次要信息,只关注主体特征间的类内差异和类间差异,但我们很难去告诉机器,要去忽略哪种次要信息,尤其是当次要信息与主体特征信息难以分开时,次要信息会增加类间差异,导致训练模型过拟合
- 人类的标签思维,本质是从事物的单一属性出发,是刻板僵化的,是智能的片面反映。图像信息在不同角度的解读下,具有不同属性,如果你将上述图像分为:人类装扮的 和 非人类装扮的,那么可以将其中的两张图归为人类装扮类,剩余的为非人类装扮类。那么这种分类标准和动物种类有什么本质区别吗?
人类的标签思维,是概念层级某一层上的实例描述。这句话什么意思呢?举个例子,在生物分类学上,存在一个层级型的划分依据,把自然界的生物按照:界门纲目科属种的层次结构划分,比如,黑猩猩物种 界:动物界 门:脊索动物门 纲:哺乳纲 目:灵长目 科:猩猩科 属:黑猩猩属 种:黑猩猩。而我们脑海中“黑猩猩”的标签,是在一个最常见的认知层次上去认知的,如果它和一个汽车放在一起,我们也可以认为它属于“动物”标签,如果它和牛放在一起,我们可以认为它是“哺乳动物”标签,它和猿猴放在一起,我们认为它是“黑猩猩”标签。那么机器学习,该如何胜任这种划分?它能同时学到,黑猩猩,既有“动物”标签,也有“哺乳动物”标签,还有“黑猩猩”标签吗?
我想是不太容易的。其实事物本身的存在是客观的,而标签是主观产生的,标签来源客观事物从不同角度出发的一种属性。如果按照标签思维去训练第一种分类标准,是得不到第二种分类的判断,反之亦成立,所以打破这种固有缺陷,就必须从实体角度出发,而就是将多种概念属性与实体联合,让机器学到的是一个戴眼镜穿衣服的狗,一个不戴眼镜不穿衣服游泳的海狮。
概括地讲,人类的标签思维是为视觉感知与语言表达需要的一种折衷,标签最大的用处在于交流与储存,而对于视觉感知来讲,“标签”是一种片面的图像表征,对于智能机器来讲,它应该学到编码更多信息的层级表征,而不单纯是标签
Faster RCNN系列深度网络成功的直观原因
2018年5月23日补充: Faster-RCNN的设计成功很大程度上取决于,多个环节利用了人类视觉本身处理目标的先验能力,比如:
- 我们通过大致扫一眼来看到目标物体大概在那个位置--RPN网络
- 我们在候选出的区域具体判定区域内的物体是什么类别--Fast RCNN网络
在faster-rcnn里面,Vgg-16网络预训练出的 特征图(feature map)实际表征了一种数值化的中间抽象概念,而从表征中间抽象概念到标签概念的信息传递是一个有损失的信息降噪、压缩编码过程。这符合人类本身的对事物的认知:试图从事物中取概括一般的内涵,这种内涵在丰富的外延下,保持着鲁棒不变性,反映在图像的像素到抽象概念上,就是从数值表示含义上的不断抽象。
端到端的学习,让中间产生的语义性、概念性的特征或者表征,不在可见,限制了网络推理的功能,faster-rcnn所具备的思想实际在端到端的过程上利用了一些人类的先验知识,它将先验知识反映在网络架构的设计上,所以下一步的网络应该是一种特征概念开放式的网络,在此基础上可以进行因果推断
总结一下,标签本质是一种偏见,是一种局限的智能,标签思维的引入使得机器学习面临着对抗样本的考验。而要解决这一问题,一方面需要重新定义事物的概念,另一方面,需要人的推断来介入