Capsules Network
2018.4.25
引言
因为最近同时在看Matrix Capsules with EM routing (https://openreview.net/pdf?id=HJWLfGWRb)和人体姿态估计相关的论文如Associative Embedding, stacked hourglass等,我渐渐发现了这两类研究方向在核心思想上的一些共通之处,即自下而上地获得全局信息,利用全局信息去解析局部特征,并进行预测。
概括地讲,近年来很多取得成功并广泛应用的深度网络设计都蕴含着这一思想,比如Deep Residual Net中的残差模块,Densely Connected Network卷积层的全连接,Fully Connected Network中的特征融合,U-net中的反卷积,还有Stacked Hourglass,其中 hourglass的设计更是淋漓尽致地表达了这一思想,不断pooling获得全局信息,然后结合局部信息进行unsampling,方法简单粗暴,通过关节点位置的监督约束来回归出heatmap。
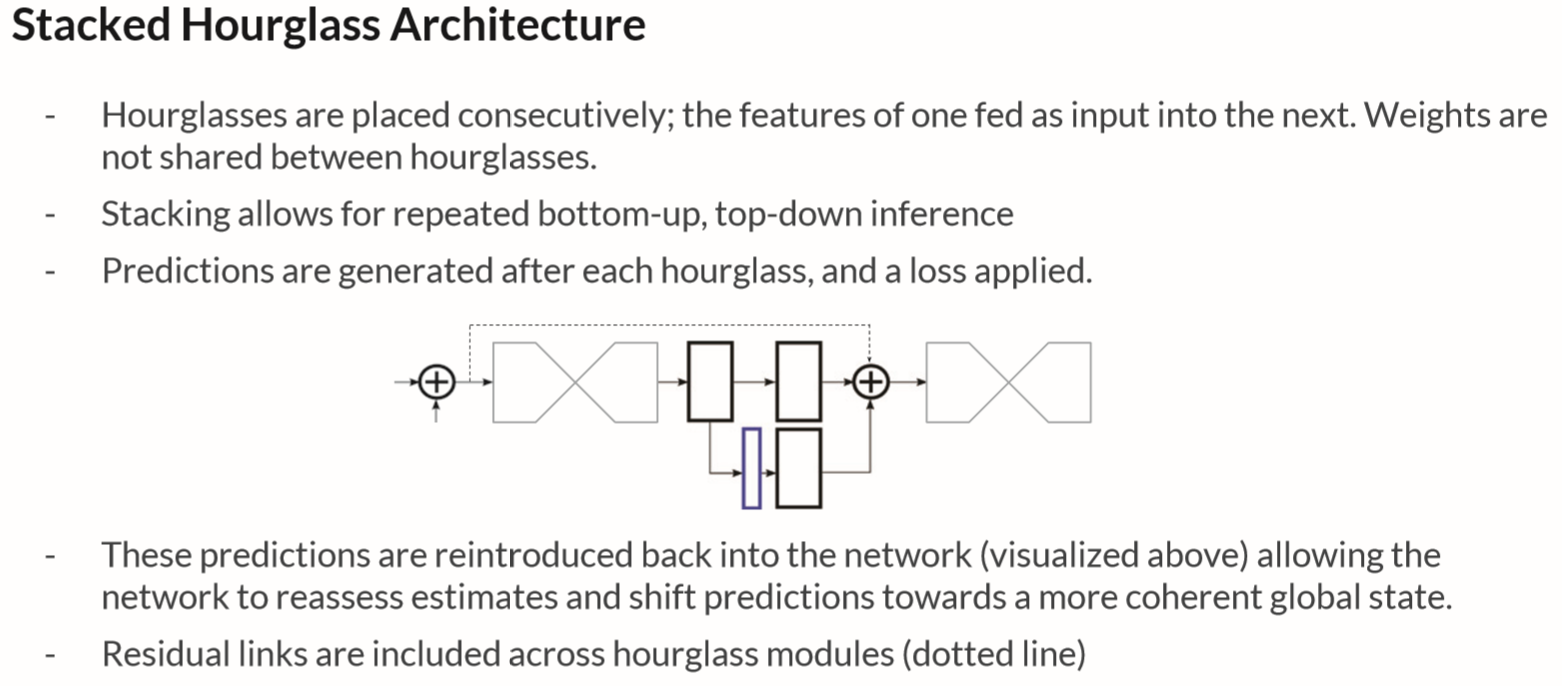
上述网络设计之所以能够成功一方面和网络层数愈来愈深,还有所谓的Trick有关,另一方面很大程度上是因为它们的设计都在把较为原始的特征信息与加工后的特征信息相融合。
为什么这样的设计是有效的?或者说如果不这样设计,网络还会起作用吗?
思考这样的问题能让我们看到问题的本质,那就是这些网络全都是基于卷积网络的架构,而卷积网络中的Pooling层的设计初衷为了得到粗略的响应位置,这会导致精确特征信息的丢失,信息丢失是不可逆的,那在一些需要精确信息的视觉任务中,而能够挽救的方式就是结合原始信息与加工后的信息。可以说,这些设计方式的成功在于它们解决了信息损失的问题。
然而在上世纪80年代卷积网络中的pooling层被设计出来时,要解决的是图像目标在平移,变换后时依然能够有着相同的输出响应。它并没有考虑日后的一些极其复杂的视觉任务,比如图像分割需要产生一个pixels wise的热值图,分割任务面临的是像素级别的预测,而大多数研究者遇到此类问题,往往是在宏观层面去设计一个更复杂的网络结构去解决问题,这样做是在使模型复杂化,针对他们特定的任务或者数据集而发挥作用,虽然说一定程度弥补了基础网络的能力,但却牺牲了设计对不同视觉任务的泛化能力。如果我们能从基础CNN固有存在的问题出发,那么是否能达到事半功倍的效果呢?
直到在2017年Hinton指出了在CNN中的固有缺陷,pooling层会导致精确特征信息的丢失,在较低层,这种丢失反映在空间信息上,如果在较高层,语义特征信息的丢失,就会让网络发掘不到更抽象的信息。所以Hinton提出了一种新的网络设计方式capsules net,并证明其能用更少量参数超过CNN性能,这种网络具有仿射变换鲁棒性,更擅长处理重叠问题。而在我的理解看来,他实际上提出的是一种新的信息无损失传递计算方式。从一定程度上讲,这种新的计算方式可以应用到已有的任何卷积网络框架中。
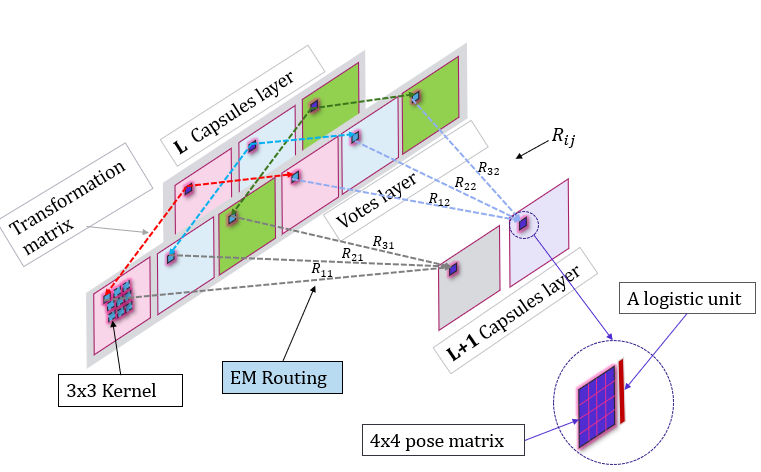
如下是matrix capsules with EM routing的核心思想,我按照论文给出的思路,形象地画出了一幅前向计算的示意图。还有论文核心路由算法的公式精简版。


#人体姿态估计
目前人体姿态估计任务面临的都是图像中人体2D姿态的关键点的回归问题,如果考虑到多人姿态估计,就要涉及到图像的解析问题,即某个关节点到底要分给谁,这是多人重叠问题的难点。当下研究者一般从两个角度去分析这一问题:bottom-up和top-down,即自下而上和自上而下。 在人体姿态估计领域内的研究,自上而下或者自下而上的图像解析都反映在了研究者的设计技巧上和网络结构的设计上,基础网络块都是CNN,还有一些更高层次的设计。而capsules网络独特的一点是,其本身的计算方式就蕴含了一种解析思想。
它将连续两个featuremap层中,较高层的capsules单元视为“因”(先验-隐变量),较低层的单元视为“果”(数据),然后建立高斯混合分布,它从数据生成角度出发,可以理解为在某一层次的特征级别中,去寻找整体特征与局部特征的关系,即每个低层的capsules试图去在高层寻找一个可以解释(生成)它的母capsule,即似然:P(子capsule|母capsule)。同时,高层的capsules也在寻找并不是偶然产生的来自低层capsules投票产生的紧密簇,这个紧密簇代表许多跟它有强烈关系的低层capsules,如果高层的某个capsule发现了低层capsules越趋于一致(越聚集,就是更服从该capsule的高斯分布),这就意味该capsule与低层capsules的关系总不确定度越低,信息熵越低,那么这个capsule越容易激活。这一过程实际上同时蕴含了bottom-up和top-down,而且基本不存在信息丢失的问题。所以这是我在开头提到为什么Matrix Capsules with EM routing和人体姿态估计的hourglass思想上相通,所以我自然地考虑想把capsule运用到人体姿态估计。
- 补充:4月26日
Facebook提出了DensePose,密集人体姿势估计是指将一个RGB图像中的所有人体像素点映射到人体的3D表面
#潜力 Capsules被设计的初衷并没有考虑复杂的视觉任务,比如人体姿态估计,那么如何去将它运用到人体姿态估计呢?
一个简单粗暴的方式就是,直接那它的路由计算去替代CNN的pooling计算,然后网络设计上去模仿当下流行的网络架构 > 补充:4月27日 2018CVPR 提出了Detail-presering pooling in Deep network(https://arxiv.org/pdf/1804.04076.pdf) ,它直接指出来CNN maxl-pooling或者average pooling存在的只选取最大而忽略与周围像素的关联性,一个重视关联性却又直接抹平,并且在实际梯度计算中也有一些drawback,所以该文提出了这个新方法,一句话概括,就是在池化过程中学了一个动态的weight (来自德国学者,我觉得我的想法跟他有点像)
另一种就是利用capsules本身能够保留精确的空间特征信息,来设计与人体姿态估计匹配的网络结构,比如设计一个heatmap层去加入到capsules网络中去,整个网络即不存在分辨率下降的问题。
值得提到的一点是,hinton在提出capsules时,他强调了这种设计方式对于处理2D数据和3D数据,是性能上一致的,而matrix capsules with em routing的实验数据集就是一个3D数据集smallNorb,数据集是5类玩具,5个实例,在18个不同方位角,在9种不同高度下,在6种不同光照条件一共下采集了24300的照片,算法在该数据集上达到state-of-art。而人体2D姿态估计是很容易产生在3D场景下姿态的变换问题,所以我个人认为,capsules能够从人体2D姿态在全方位视角下捕捉产生的数据中去寻找一种3D上的全局信息,因为在matrix capsules with em routing这篇论文就在强调capsule中的 4x4 pose matrix 就在学习观察者和物体实例之间的视角关系。
#未来工作和难点 实现hourglass相关代码和capsulesEM相关代码,DPP的cuda代码也可以考虑相,将算法融合
实现hourglass相关代码和capsulesEM相关代码,将两者算法融合。
目前在人体姿态数据集上,性能排名:
MPII
①单人姿态估计
表现最好的是2018 ArXiv上来自中国科学院的Multi-Scale Structure-Aware Network for Human Pose Estimation论文 https://arxiv.org/pdf/1803.09894.pdf
(这篇论文包含Hourglass的设计)
②多人姿态估计
表现最好的是NIPS2017 Alejandro Newell发表的Associative Embedding: End-to-End Learning for Joint Detection and Grouping论文 https://arxiv.org/pdf/1611.05424.pdf (hourglass原作者的多人姿态估计设计)
MS COCO

2017年在COCO数据集上性能表现最好的来自Face++提出的Cascaded Pyramid Network for Multi-Person Pose Estimation https://arxiv.org/pdf/1711.07319.pdf
其设计思想和stacked hourglass有异曲同工之妙,它包含了GlobalNet和RefineNet,不过CPN采用的是top-down的设计方式,FPN网络先检测bouding boxes,然后进行single pose estimation,它可以处理multi-person的姿态估计
1 | 原创, 禁止转载 |