1. 引言
《stacked capsule autoencoders》使用无监督的方式达到了98.5%的MNIST分类准确率。 Stacked Capsule Autoencoders 发表在 NeurIPS-2019,作者团队阵容豪华。可以说是官方capsule的第3个版本。前两个版本的是:
当然还有最早的Transforming Auto-encoders,发表在2011年ICANN,论文第一次引入“capsule”的概念。值得一提的是,这篇论文的作者是Hinton、Alex Krizhevsky等人,对,是AlexNet的Alex。原来Alex本人在2012年发表AlexNet之前在研究这种“奇怪”的东西。2011年的他可能没想到,第二年的他们,为了参与ImageNet大规模数据集图像识别挑战赛而设计的一款基于的传统CNN的AlexNet,引爆了接下来已经持续7年之久的“Deep Learning”潮流,现如今CVPR 2020投稿量都过10000了,是谁惹得“祸“的还不清楚吗?
2. 概念
从2017年开始, Hinton等人研究的Capsule Network得到了深度学习社区的大量关注。可以说Capsule Network在反思CNN的一些固有偏见,比如CNN的学习过分强调不变性(invariant )特征的学习,数据增强也服务于这一目的。而这样做,实际上,忽略了一个真实世界中的事实:
1)物体-部件 关系(Object-Part-relationship)是视角不变的(viewpoint invariant), 2)物体-观察者(Object-Viewer-relationship) 是视角同变性(viewpoint equivariant)的。
equivariant:\(\forall_{T \in \mathcal{T}} Tf(\mathbf{x}) = f(T\mathbf{x})\) invariant: \(\forall_{T \in \mathcal{T}} Tf(\mathbf{x}) = f(T\mathbf{x})\)
并且Capsule强调物体的存在是因为当部件以合理的关系组合才得以存在,所以进一步引出了routing的机制,来发掘part-whole关系。
Matrix Capsule的那篇论文中提出,用混合高斯模型来学习这些关系,并提出了EM routing的算法,它从GMM和EM的角度,解释为更低层capsule与更高层capsule之间的自聚类算法。然而这种计算一旦放在前向传播会大大增加计算量,这也是其模型理论受限的部分, 所以其实验数据集主打还是MNIST, SmallNorb,如果换做更大一点的ImageNet, COCO,不知道Capsule的精深理念能不能发扬光大。可能Hinton深知自己的先驱身份所以他应该相信后面会有人帮他填满这些实验?
不过这种Gaussian Mixture的建模方式是非常合理的,一是GMM作为生成模型,自身就具备很强的解释性,二是这种参数学习以极大似然估计的方式,不再过分依赖梯度回传的更新机制,所以GMM的思想继续用在了Stacked Capsule Autoencoder里面。
这里想说的是: 如果有人问,当前深度学习的核心理念是什么,我个人觉得,一个比较好的回答就是,学习目标形式化进而转换为参数的梯度学习。然而这样的同质研究越来越多,又越来越难以深入其内部,DL社区就开始自我反思。而Capsule的理念里面,就尝试去摆脱D中L对梯度回传的过分依赖,对卷积结构的过分依赖,所以Capsule Network本身将一些自编码器、重构、混合高斯、注意力等机制引入其中。
其实读这篇论文会感觉作者用到的技术太多了,很容易忽略它背后的动机。我个人对它背后动机的理解为: 将图像中的实例的部件及属性从像素二维空间中以像素重建的方式抽取出出来;再用重构的方式解释部件与整体的关系。这也是SACE的两个主要构成环节。
接下来,本文希望通过简洁的语言来描述该论文的主要思路,所以跳过了论文对Toy Setup的描述,直接总结了SCAE的两个主要模块。
3. Stacked Capsule Autoencoders (SCAE)
SCAE = PCAE +OCAE
(Part Capsule Autoencoder + Object Capsule Autoencoder)
以这幅官方给出的这幅示意图为例
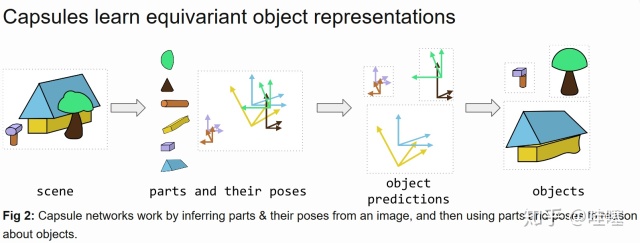
PACE
目标:将 \(h\times w \times c\) 的图像,编码成 \(M\) 个part capsules,每个part capsule能够对应图像中的一种部件part的所有属性,用多个属性构成的一个向量 \(X \in R^{6+1+z_m}\) 来表示一个part实例,这个实例属性中包括6维的姿态,1维的存在概率和 \(z_m\) 维的自身独特性特征。
编码方法:采用CNN+Attention Pooling 方式:
\[ h\times w\times c \Rightarrow M \times X \]
解码方法:可学习的\(M\)个 \(11\times 11\)大小的模板+仿射变换(6维姿态导出)
学习训练方法:用可学习的模板,进行高斯混合来重构原始图像+所有位置上的像素数据的极大似然估计
OACE
目标:把 part capsules当成 \(M\) 个 \(X\) 构成的集合,使用 Set Transformer学习集合中元素与元素之间的成对关系以及高阶的关系,来预测 \(K\) 个object capsules,每个object capsule能够对应图像中的一个物体的所有属性,用多个属性构成的一个向量 \(Y \in R^{9+1+z_k}\) 来表示一个part实例,这个实例属性中包括9维的object-viewer-matrix,1维的存在概率和 \(z_K\) 维的自身独特性特征。然后对每个object capsule 使用MLP解码出,每个object capsule与所有part capsule之间的隶属关系,使用高斯混合模型来建模,即part capsule m的姿态 \(x_m\)的可以看成是多个object capsule的贡献的高斯混合, 那么第 \(k\) 个object capsule 对第 \(m\) 个part capsule的贡献为 \(p(x_m|k,m)\)
编码方法:Set Transformer 学习集合中各个元素的pair-wise关系以及高阶的关系,是permutation-invariant的模型。输出 \(K\) 个object capsules实例
解码方法:用 \(K\) 个MLP预测高斯混合模型(详见论文中的公式)的候选投票,一个是方差,然后计算出高斯混合模型每个高斯成分的均值和方差,这样就可以计算出 \(p(x_m|k,m)\)。
学习训练方法:部件part-capsule及其属性,被物体object-capsule整体下的高斯混合来进行重构解释的极大似然估计
4. AAAI 2020 Hinton发表了关于Stacked Capsule AutoEncoder的演讲
演讲地址在:Geoffrey Hinton:Stacked Capsule Autoencoders(堆叠胶囊自编码器) (AAAI 2020)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
矩阵具备很好的同变性(equivariant)的性质,仿射矩阵可以发挥出出奇的作用。
他还提到了一个很有意思的概念:Coincidence Fitering
他指出了现在的CNN的问题 并没有很好的利用--偶然性过滤,但是Transformer的注意力机制中体现出了偶然性过滤
我比较喜欢,这种用恰到好处的语言来描述提炼出一个抽象的解释性名词,既形象生动,又直指核心问题
什么叫偶然性过滤?
我个人的直觉理解是,CNN主要做的是卷积核的权重与激活值的矩阵乘法(或者说是向量的内积),那么由于输出目标监督是稀疏的(groudtruth往往是稀疏的,无论是分类还是回归,坐标还是热图),就会让中间的激活也倾向于是稀疏的,也就是说,大部分的权重矩阵与激活向量的乘法运算时对应元素的取值倾向,是无关的,或者说他们的对应取值是偶然的,这样的值是不显著的,容易会被不激活,但是问题是,这种稀疏激活模式,并不是发生在两个高维激活向量之间,而是可学习的权重和神经元的激活值之间,而真正的偶然性过滤需要发生在两个高维向量之间的某些对应元素上,比如两个10000维的向量在第2437位上具备相似的取值,而其他元素对应不存在什么关系,这种两个偶然性中出现的一致是不平凡的,那么其他平凡的偶然性就会被过滤掉。Transformer中的注意力机制就是高维向量间的内积,就会形成一种covariance structure,它会过滤掉大部分偶然的输入 (非目标输入),只有契合该covariance structure的输入才能形成明显的激活!
(上述是我的直觉理解,描述不一定准确, 期待有更多的讨论和解读)
 > [!NOTE] >(~而且有时候,我们的实验结果和结论都有可能是“偶然的”)
> [!NOTE] >(~而且有时候,我们的实验结果和结论都有可能是“偶然的”)
演讲地址在:Geoffrey Hinton:Stacked Capsule Autoencoders(堆叠胶囊自编码器) (AAAI 2020)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili 另外,我也整理出了关于 Dynamic Routing Between Capsules,Matrix capsule with EM routing 和 Stacked Capsule Autoencoders 的PPT。百度云盘地址:https://pan.baidu.com/s/1BCdJiNWGqD-SNao7Lmv4sw 提取码:e58t
Hinton联合了很多的学者在不断迭代着Capsule的概念和技术,不断地引入新鲜的东西到深度学习中。一方面我觉着我们需要相信大佬的直觉,另一方面我们也不能盲目地追捧,还是要尽量抛开作者光环,去探讨论文研究中是不是拥有着奇思妙想或者醍醐灌顶的东西存在。