Uber团队在2018NeurIPS上提出了CoordConv,它分析了卷积神经网络在进行坐标预测时存在的缺陷,并引入坐标嵌入方式来解决这个问题。但本人也注意到网上有人质疑这个方法,比如量子位小编报道了一个国外博主的质疑。本人看了他的质疑,他主要是在强调:
用完全数学的方式就可以构造出一个由one-hot heatmap映射到坐标的神经网络,并且根本不需要训练
实际上,他讲的这个和soft-argmax对heatmap求积分得到坐标的方法很像。首先,我想说,数学的归纳是一种非常高阶的手段和智能,很多问题本身就可以直接去用数学问题去解决,但是,这是直接注入了人类专家的知识,并不是神经网络本身从头学习到的(from scratch)。
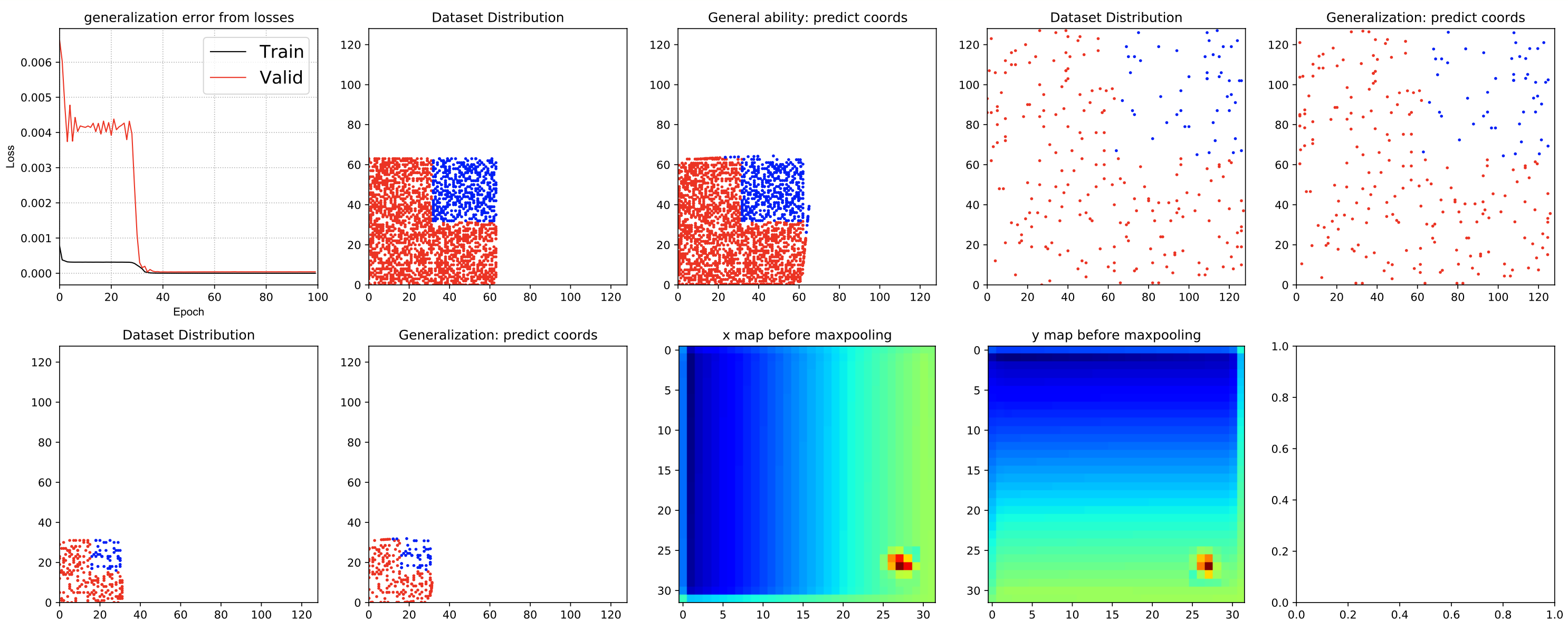
CoordConv探讨的是,神经网络在拟合能力上以及泛化能力上存在的缺陷。CoorConv的亮点之一在于构造数据集划分的巧妙,一个是普通的train和test坐标数值分布一致的数据集,另外一个是test中的坐标取汁是train中完全没有的取值分布的数据集(正方形的1/4一角区域拿出来做测试),后者在考验模型在未见到的坐标分布上的泛化能力。
该论文的实验以及本人的实验验证发现,大多数普通的MLP或者Conv是很难调出一个好的泛化效果。而CoordConv神奇之处在于,它通过训练的方式来获取一种数学上的严格计算能力,结果确实做到了,因为train loss 和 test loss同时收敛到0,模型可以100%地精确预测坐标,这对于普通神经网络真的挺难的。
本文主要进行了如下的代码实验和分析:
- 数据集:构造由坐标生成的one-hot heatmap与数值坐标之间的数据集:遵循An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution的quarter split方式。
- 模型:利用神经网络加坐标嵌入(MLP+Coord and Conv+Coord)的方式进行拟合与泛化测试。
- 效果分析与发现:用Pytorch复现验证了An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution中Superivised Coordinates Regression任务的CoordConv的泛化性能!
- 可视化神经网络的某些层和输出,来发掘神经网络学习坐标信息的过程
数据集的构造
构造一个简单的数据集:由非归一化坐标构造表示位置的One-hot heatmap: \[ (x,y)\rightarrow H\in\mathbb{R}^{h\times w} \]
\[ H(j,i)=\left\{\begin{matrix} 1 & \text{if}\,\,i=x\wedge j=y\\ 0 & \text{if}\,\,i\neq x\vee j\neq y \end{matrix}\right. \]
其中,输入数据是\(H\),标签是\((x,y)\)
这个数据集还有一个特殊的部分就是train和test的划分。我们根据Coordconv论文,考虑了两种划分:
- train set和test set采取uniform的位置数据采样
- train set和test set采取quarter split的位置数据采样,即train set是在一个正方形内3/4区域内采样,test set在正方向剩下区域1/4采样
第二种数据集划分方式,更能考验模型的泛化性能,即在未见到的数据上的预测能力。
代码如下:
1 | import torch |
(3, 64, 64)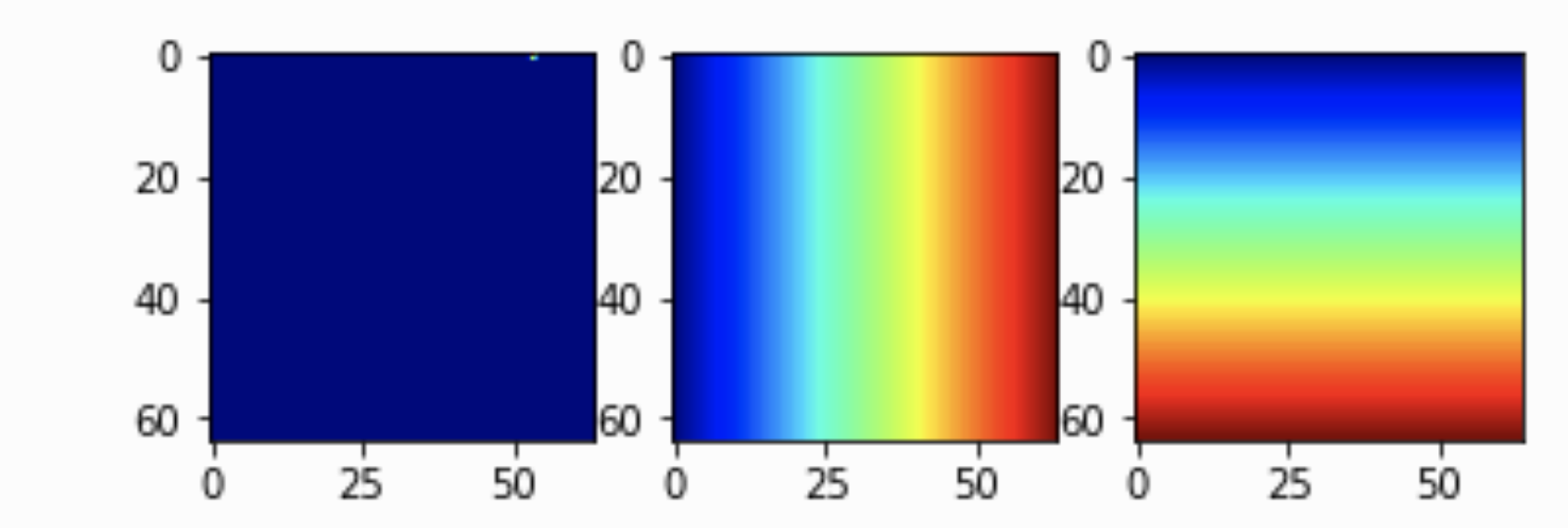
上面三幅图从左至右分别是:
- 构造的表示坐标位置的One-hot heatmap编码;
- 在x方向上的坐标信息嵌入,取值在[-1,1]
- 在y方向上的坐标信息嵌入,取值在[-1,1]
MLP预测坐标的能力怎么样
一开始,我们最直接的想法就是,构造一个简单的多层感知机MLP做直接的映射:从one-hot heatmap 到 \((x,y)\)。
代码很简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class net(nn.Module):
def __init__(self, input_dim, h, output_dim):
super().__init__()
self.l = nn.Sequential(
nn.Linear(input_dim, h),
nn.LayerNorm(h),
nn.ReLU(),
nn.Linear(h, h),
nn.LayerNorm(h),
nn.ReLU(),
nn.Linear(h, output_dim),
)
def forward(self, x):
x = x.flatten(1)
return self.l(x).sigmoid()
然后我们用Uniform的数据集划分进行训练测试。结果如下:
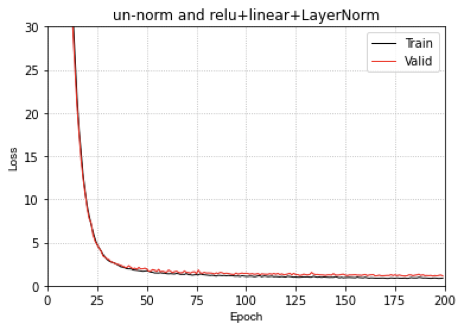
我们看一下MLP在Uniform数据集划分上的预测结果
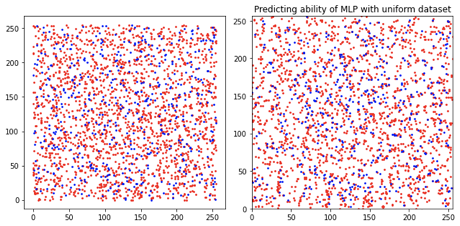
左图是数据集的位置的真实分布(红色是Train set,蓝色是test set),右图是MLP的预测结果。
从上面的结果上来看,对于一致分布的数据集,整体上,MLP的表现似乎还可以,
那如果换成Quarter Split划分的数据集会怎么样呢?
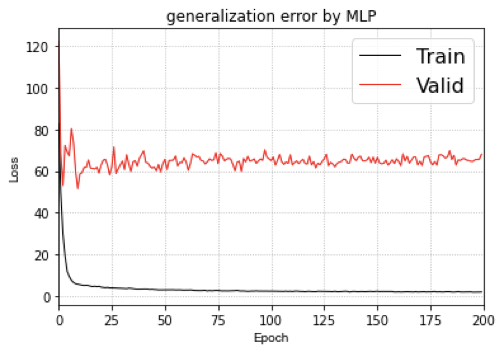
好像MLP就无法具备泛化特性了矣?
Traing loss和Valid loss(就是test集合)的差距(泛化误差)很大,
我们再看看预测的结果。
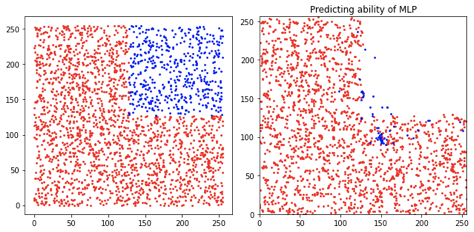
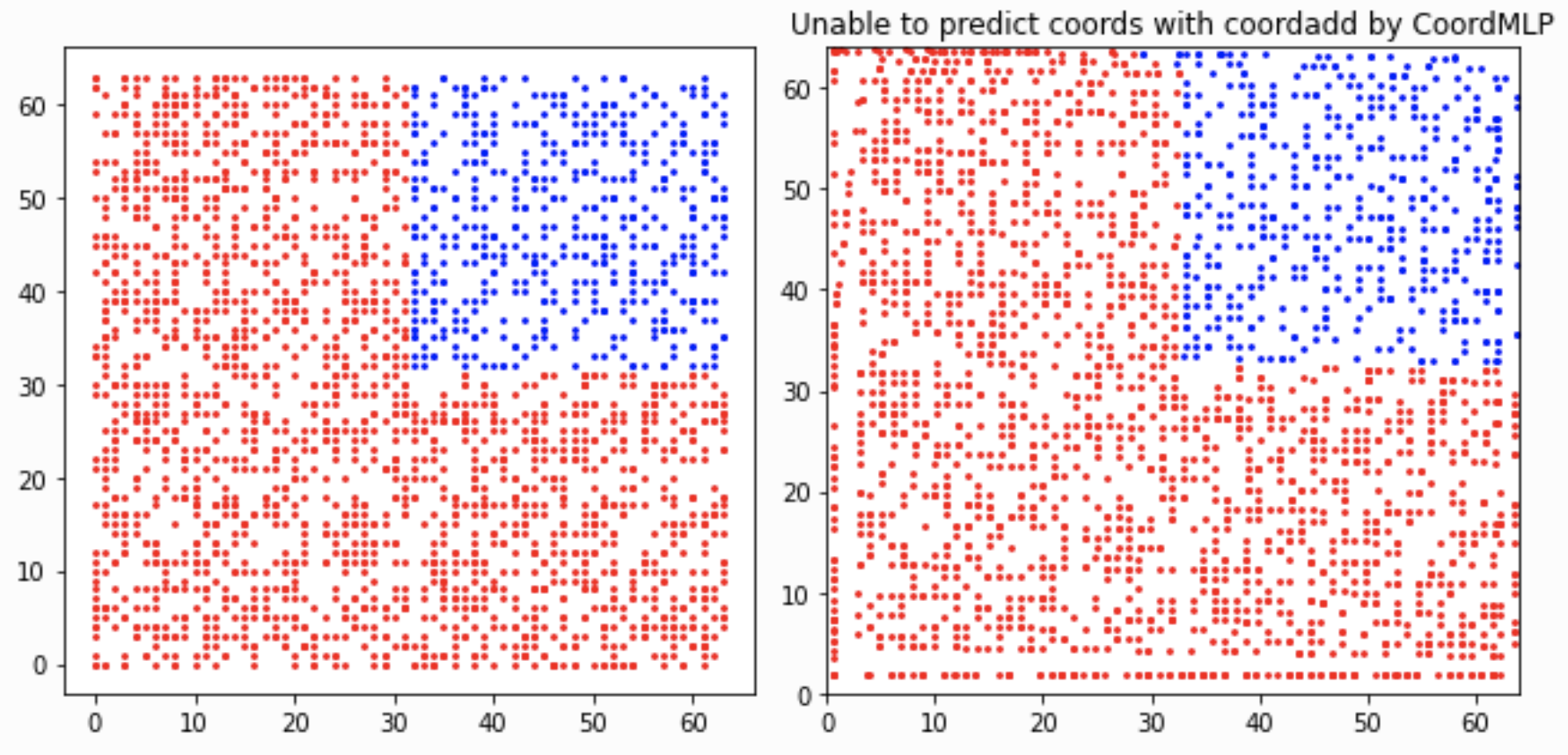
左图是数据集的位置的真实分布(红色是Train set,蓝色是test set),右图是MLP的预测结果。
这一结果更加印证了,MLP完全只是过拟合了Train set,而不真正具备了位置预测的能力。
而对于Uniform的数据集的样本分布,Test和Train的分布几乎一致,MLP所谓的预测坐标,只是因为它“见过”类似的样本,“学习了”它该输出什么才能“满足loss小的需求”!
那我们是不是可以给MLP加入坐标嵌入技术来改进提升其泛化能力?
CoordMLP 怎么样?
1 | import torch.nn as nn |
1 | [0/0]:train loss:66.604 |
1 | import matplotlib as mpl |
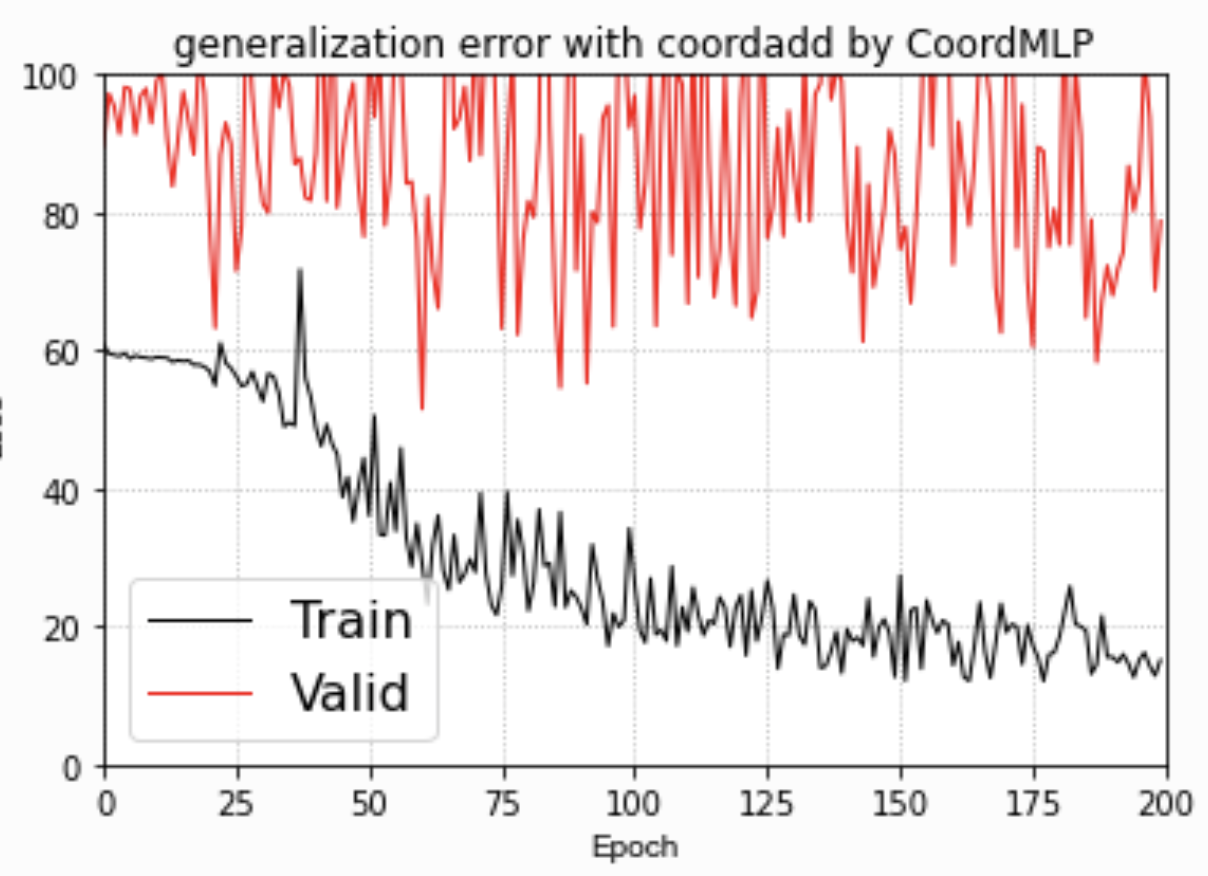
根据Loss看来,CoordMLP 嵌入坐标信息的MLP还是不具备好的泛化能力!
1 | fig, ax1 = plt.subplots() |
1 | net( |
可视化MLP的权重参数
通过可视化MLP权重参数的取值,我们发现了不同层的取值范围的分布是不同的
但是并没有获得什么有意义的信息和解释
1 | train_set = heatmap_generator(num=2000, seed=0, uniform=True) |
1 | train_set = heatmap_generator(num=2000, seed=0, is_train=True, coordadd=True) |
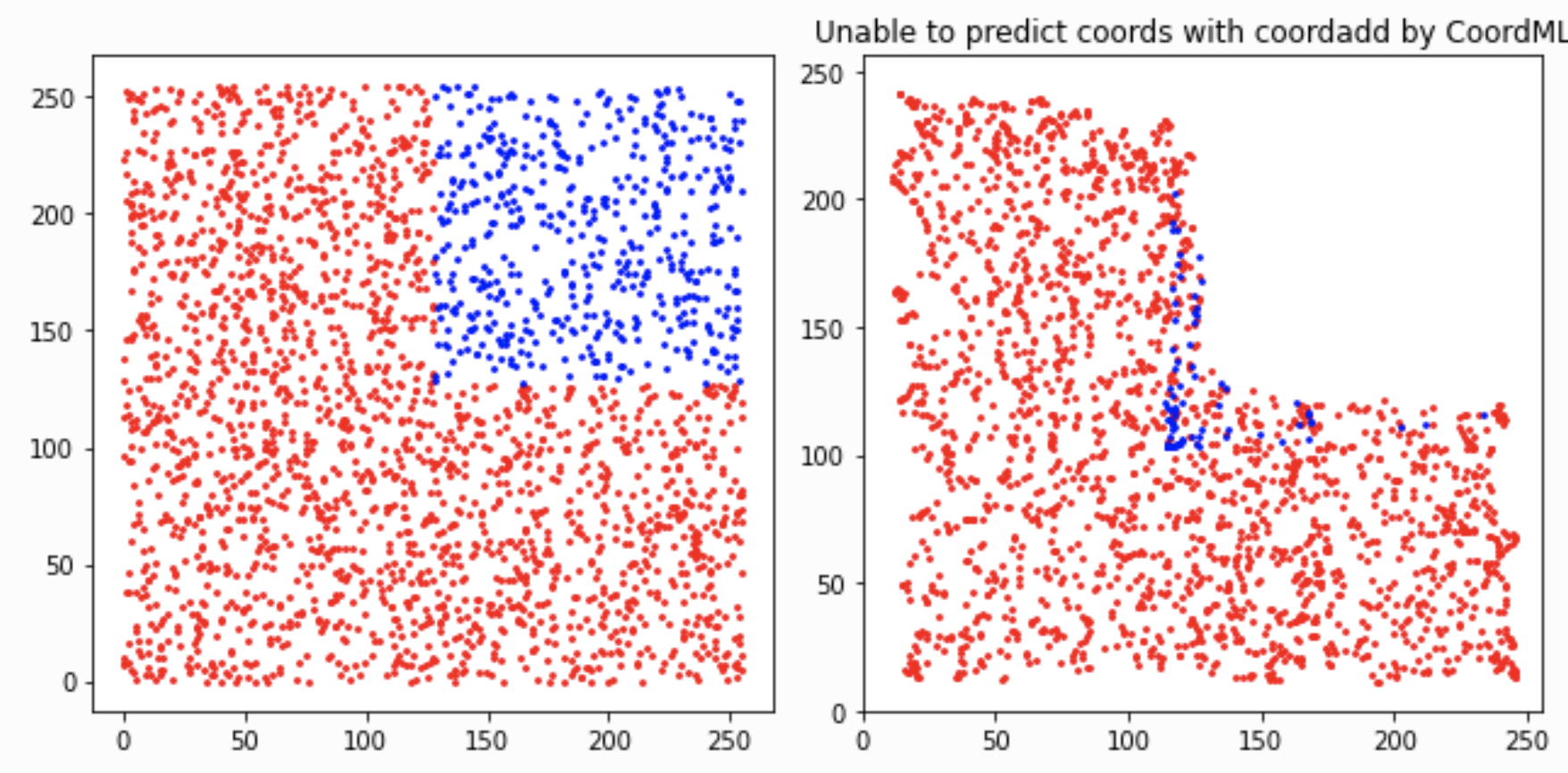
嵌入坐标信息的CoordMLP 像单纯的MLP一样,好像也不具备预测坐标的泛化性能
把heatmap嵌入Coordinate Maps,然后Flatten,然后送进MLP中,模型可以在训练集上预测得很好,但是却不具备泛化能力。可以看到,这种训练和验证集的Quart split划分方式还是非常有趣,并且是有难度的。
CoordConv 怎么样呢?
接下来我用PyTorch复现下面这个论文的部分内容。
An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution论文提出了一种坐标嵌入的方法
我们根据论文官方放出的Tensorflow代码,用PyTorch严格按照其网络结构重写。训练的优化器、学习率及其weight decay也尽可能和它保持一致。
1 | import torch |
1 | [0/0]:train loss:1027.723 |
......
......
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114[489/0]:train loss:313.746
[489/0]:valid loss:498.646
[490/0]:train loss:331.695
[490/0]:valid loss:570.283
[491/0]:train loss:308.808
[491/0]:valid loss:543.668
[492/0]:train loss:331.526
[492/0]:valid loss:609.543
[493/0]:train loss:314.055
[493/0]:valid loss:530.251
[494/0]:train loss:303.886
[494/0]:valid loss:557.143
[495/0]:train loss:321.458
[495/0]:valid loss:543.295
[496/0]:train loss:311.247
[496/0]:valid loss:497.568
[497/0]:train loss:326.582
[497/0]:valid loss:515.231
[498/0]:train loss:333.465
[498/0]:valid loss:553.942
[499/0]:train loss:308.450
[499/0]:valid loss:573.775
[500/0]:train loss:304.610
[500/0]:valid loss:585.026
[501/0]:train loss:325.851
[501/0]:valid loss:577.704
[502/0]:train loss:313.319
[502/0]:valid loss:510.165
[503/0]:train loss:301.331
[503/0]:valid loss:563.254
[504/0]:train loss:294.513
[504/0]:valid loss:550.867
[505/0]:train loss:337.322
[505/0]:valid loss:405.499
[506/0]:train loss:210.640
[506/0]:valid loss:440.354
[507/0]:train loss:177.821
[507/0]:valid loss:372.500
[508/0]:train loss:152.111
[508/0]:valid loss:314.090
[509/0]:train loss:150.206
[509/0]:valid loss:531.095
[510/0]:train loss:131.546
[510/0]:valid loss:320.094
[511/0]:train loss:124.478
[511/0]:valid loss:348.056
[512/0]:train loss:82.704
[512/0]:valid loss:138.187
[513/0]:train loss:93.763
[513/0]:valid loss:59.943
[514/0]:train loss:28.917
[514/0]:valid loss:83.261
[515/0]:train loss:26.591
[515/0]:valid loss:103.014
[516/0]:train loss:20.655
[516/0]:valid loss:90.283
[517/0]:train loss:14.670
[517/0]:valid loss:86.509
[518/0]:train loss:7.979
[518/0]:valid loss:81.485
[519/0]:train loss:5.293
[519/0]:valid loss:82.389
[520/0]:train loss:6.404
[520/0]:valid loss:79.925
[521/0]:train loss:4.992
[521/0]:valid loss:73.615
[522/0]:train loss:2.514
[522/0]:valid loss:68.852
[523/0]:train loss:3.168
[523/0]:valid loss:61.463
[524/0]:train loss:2.194
[524/0]:valid loss:58.418
[525/0]:train loss:3.485
[525/0]:valid loss:55.320
[526/0]:train loss:2.697
[526/0]:valid loss:46.612
[527/0]:train loss:4.031
[527/0]:valid loss:42.675
[528/0]:train loss:3.537
[528/0]:valid loss:35.026
[529/0]:train loss:2.433
[529/0]:valid loss:21.490
[530/0]:train loss:1.950
[530/0]:valid loss:6.599
[531/0]:train loss:1.498
[531/0]:valid loss:0.874
[532/0]:train loss:0.641
[532/0]:valid loss:0.786
[533/0]:train loss:1.632
[533/0]:valid loss:0.256
[534/0]:train loss:0.318
[534/0]:valid loss:1.699
[535/0]:train loss:3.042
[535/0]:valid loss:1.706
[536/0]:train loss:1.189
[536/0]:valid loss:1.651
[537/0]:train loss:4.311
[537/0]:valid loss:1.211
[538/0]:train loss:2.011
[538/0]:valid loss:4.156
[539/0]:train loss:2.527
[539/0]:valid loss:1.380
[540/0]:train loss:1.754
[540/0]:valid loss:7.980
[541/0]:train loss:4.717
[541/0]:valid loss:7.452
[542/0]:train loss:2.004
[542/0]:valid loss:0.953
[543/0]:train loss:1.676
[543/0]:valid loss:0.460
[544/0]:train loss:1.610
[544/0]:valid loss:0.386
[545/0]:train loss:0.336
[545/0]:valid loss:0.584
......
......
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[992/0]:train loss:0.056
[992/0]:valid loss:0.034
[993/0]:train loss:0.034
[993/0]:valid loss:0.043
[994/0]:train loss:0.051
[994/0]:valid loss:0.050
[995/0]:train loss:0.041
[995/0]:valid loss:0.061
[996/0]:train loss:0.108
[996/0]:valid loss:0.389
[997/0]:train loss:0.539
[997/0]:valid loss:0.133
[998/0]:train loss:0.250
[998/0]:valid loss:0.107
[999/0]:train loss:0.247
[999/0]:valid loss:1.734
1 | import matplotlib as mpl |
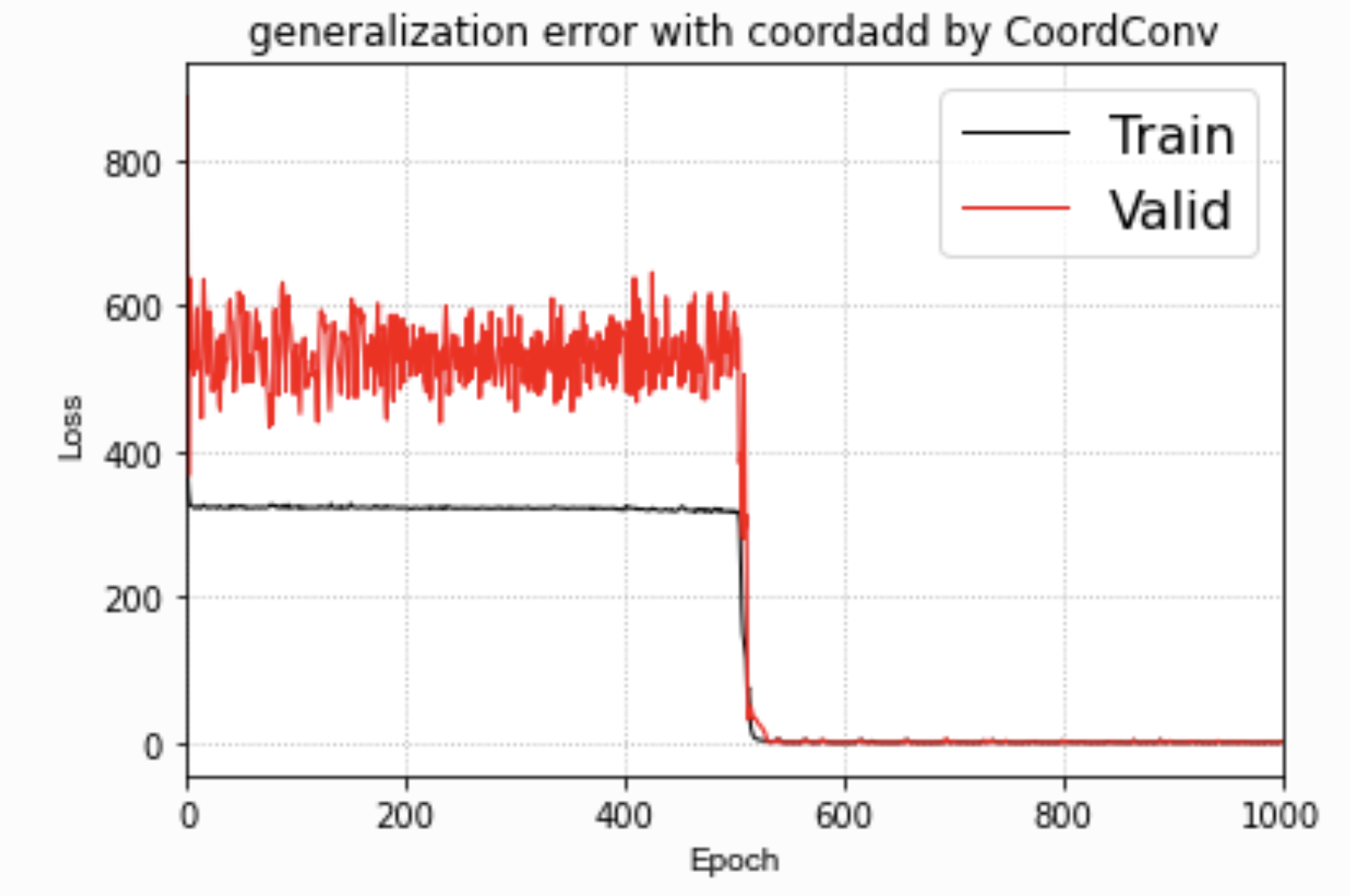
我有了一个神奇的发现,在500个周期后,train和test loss开始急速收敛!?
500个周期时,训练loss和验证的loss,开始极速下降!
我怀疑这个代价函数的优化曲面有一个非常难以跳出的局部最优解,因为我的训练集和验证集的数据分布之间有一个非常明显的GAP!
如果能有人看到这个, 对这个问题有自己的见解,欢迎和我探讨!
1 | fig, ax = plt.subplots(1, 2, figsize=(9, 4.5), tight_layout=True) |
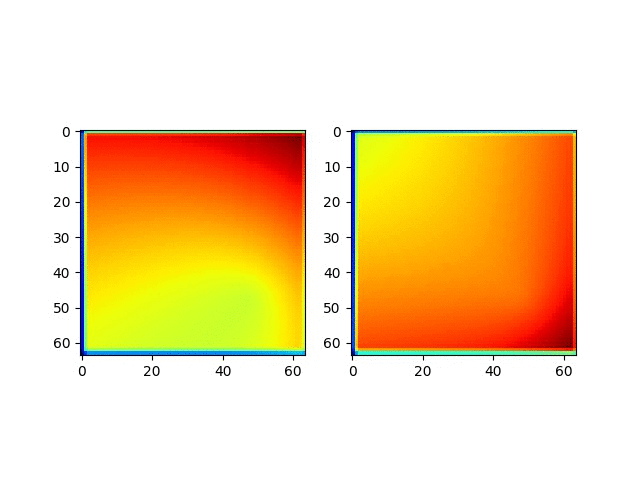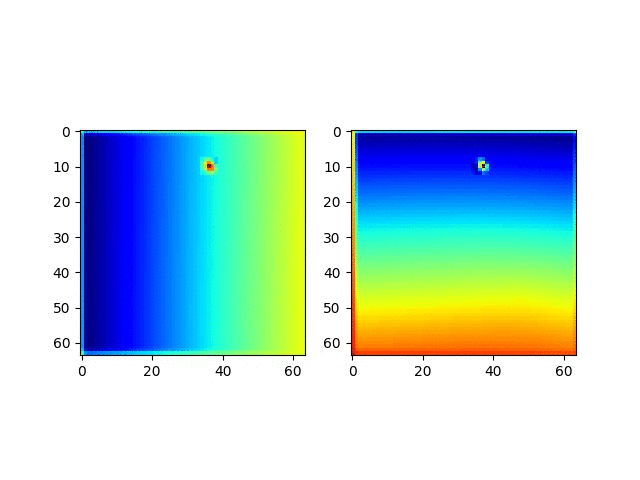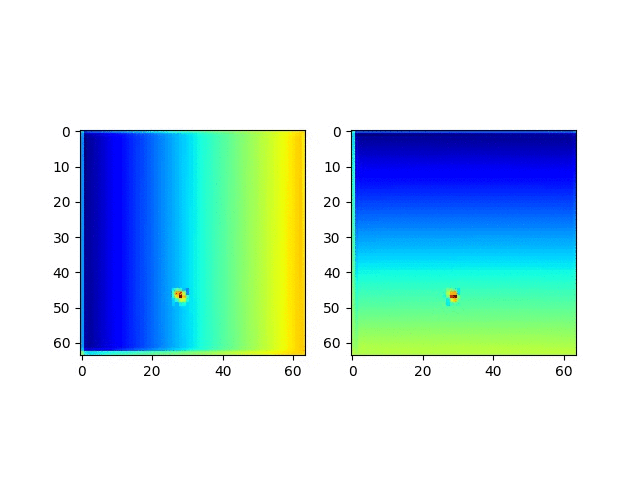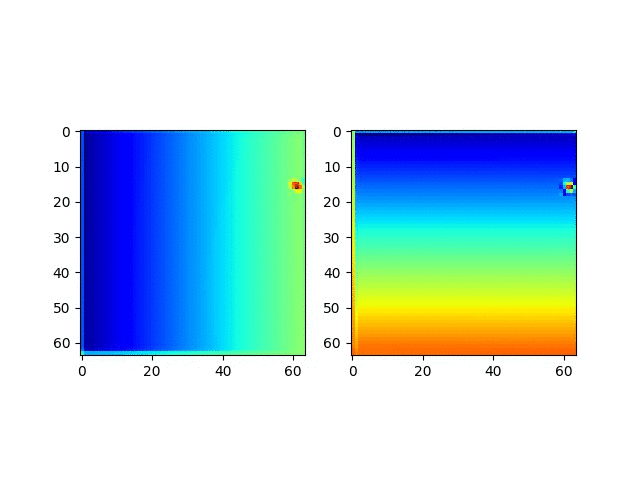
我们继续看一看CoordConv预测的坐标实际是什么样的。
很明显,这个CoordConv的网络具备了非常神奇的预测位置的能力。
并且获取这个坐标回归能力是突然在某个周期获得的!!!
我个人猜测,这个代价函数的优化曲面有一个很深的局部最小值点。Adam不断积累的梯度跳出了它。PS:这个问题在我用了更小的权重衰减之后,就解决了,CoordConv很快收敛。
论文回顾
In this work, we expose and analyze a generic inability of CNNs to transform spatial representations between two different types: from a dense Cartesian representation to a sparse, pixel-based represen- tation or in the opposite direction. Though such transformations would seem simple for networks to learn, it turns out to be more difficult than expected, at least when models are comprised of the commonly used stacks of convolutional layers. While straightforward stacks of convolutional layers excel at tasks like image classification, they are not quite the right model for coordinate transform.
Throughout the rest of the paper, we examine the coordinate transform problem starting with the simplest scenario and ending with the most complex. Although results on toy problems should generally be taken with a degree of skepticism, starting small allows us to pinpoint the issue, exploring and understanding it in detail. Later sections then show that the phenomenon observed in the toy domain indeed appears in more real-world settings.
We begin by showing that coordinate transforms are surprisingly difficult even when the problem is small and supervised. In the Supervised Coordinate Classification task, given a pixel’s (x, y) coordinates as input, we train a CNN to highlight it as output. The Supervised Coordinate Regression task entails the inverse: given an input image containing a single white pixel, output its coordinates. We show that both problems are harder than expected using convolutional layers but become trivial by using a CoordConv layer (Section 4).
Some Tricks and Visualizations:
我改进CoordConv时用到了以下的一些Tricks:
- 在靠近网络输出层之前,增加CoordConv层能够显著提升收敛速度
- 坐标归一化
- 数值尺度控制(可以获得更强的泛化特性,即对于未见到不同大小的Heatmap具备泛化特性!)
CoordConv在相同优化条件下,只用了100个周期内就很快收敛,并且获得了很强的泛化能力。
还进行了
- pooling前 map的可视化
- CoordConv在不同大小的one-hot heatmap的数据集的泛化能力测试
本文正文到此结束,后面还会继续研究,欢迎讨论,可联系我的邮箱yangsenius@seu.edu.cn
【本人原创,转发请注明来源】
「Sen Yang. The findings on CoordConv technique. https://senyang-ml.github.io/2020/09/22/coordconv/, 2020」